What exactly is inside a PowerPoint file? Are all embedded links working?
Checking all links page by page takes too much time.
Parsing the underlying XML files and checking the links is much faster.
We build a user friendly app that can be run from python, as an EXE file or as docker container that can be deployed to your infrastructure.
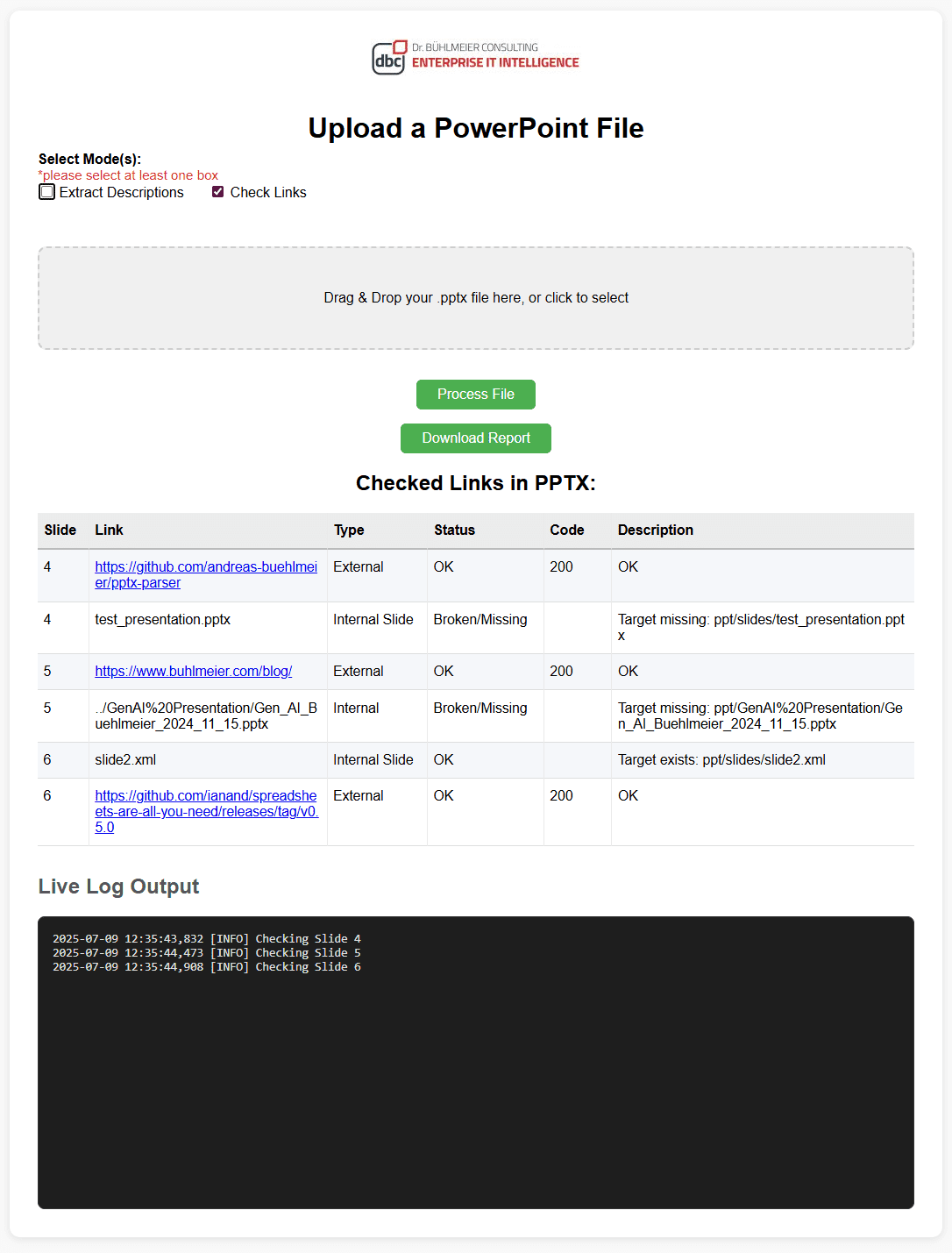
The result of the checks are displayed in a tabular format.
The Idea
PowerPoint presentations are often treated as static visual documents, but in reality, they’re structured collections of XML files zipped into a .pptx container. These files define not only the content of each slide, but also how that content is organized, referenced, and presented. We saw potential in tapping into this structure to extract meaningful information that would otherwise be hidden.
The core idea behind the pptx-parser is to read and interpret the p:cNvPr (NonVisualDrawingProperties) tags. These tags represent metadata for elements like text boxes, images, and shapes—essentially the building blocks of a slide. By parsing these elements, we’re able to uncover a rich layer of information about how a presentation is built.
Update: Introducing the Extended PPTX Parser with Link Validation
We’re excited to share that we’ve expanded this tool even further, and it’s now available as a separate project: the Extended PPTX Parser. This new version builds upon the original foundation and introduces one of our most requested features: automated link checking.
Imagine you’re working with a slide deck that contains dozens of hyperlinks—URLs, embedded file paths, or internal slide references. Manually clicking through each one to ensure it works would be tedious and error-prone. That’s exactly the kind of problem the Check Links feature is designed to solve.
With the new version, you can now:
- Choose whether to extract object descriptions, validate links, or both.
- Automatically scan every link in your presentation—whether it’s external, internal, or embedded.
- See results in a clear, interactive table that shows the status of each link.
- Download a detailed report that includes both slide object descriptions and the link check summary.
You can find the new repository at:
github.com/RaresVelnic/pptx-parser-extended
We’ve also published a new YouTube video walkthrough to demonstrate how this feature works in real time.
What It Does
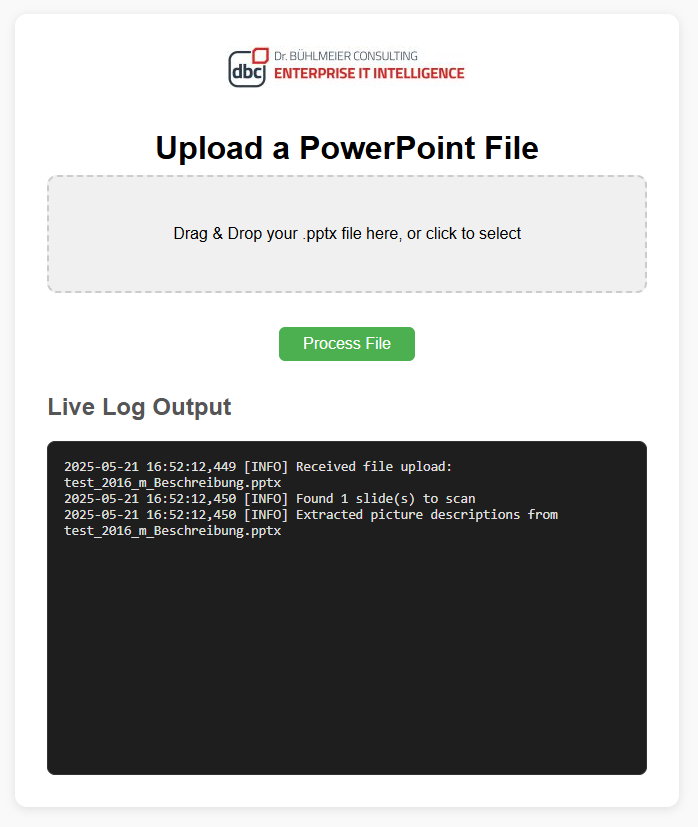
The pptx-parser operates by deconstructing the XML structure of .pptx files and extracting every instance of the p:cNvPr tag. These NonVisualDrawingProperties reveal the metadata behind each visual object on a slide—identifying their type, position, and descriptive labels.
The parser processes this data into readable summaries, such as “Textbox on Slide 3, titled ‘Team Overview’,” providing a fast and insightful view into a presentation’s structure. It also flags potential issues in the XML (such as broken references or missing attributes) and logs every step of the process, giving users full transparency into what was parsed successfully and what wasn’t.

The User Experience
Ease of use was a key goal from the start. The tool comes with a clean and intuitive GUI, allowing users to drag and drop .pptx files for immediate analysis. As the parser runs, it displays real-time logs of the operation—including both error messages and success confirmations—making the entire process visible and understandable, even for non-developers.
One of the strengths of the pptx-parser is its flexibility. It can be used:
- As a desktop application for local analysis,
- As a packaged executable for distribution to other users,
- Or deployed as a web-based application for teams needing remote access or integration into a broader toolchain.
Why It Matters
Parsing Office files is often viewed as tedious and overly technical, but it doesn’t have to be. The pptx-parser offers a bridge between visual design and structured data, enabling automation, validation, and even insight discovery in environments where presentations play a central role.
Whether you’re auditing slide content for consistency, extracting metadata for compliance reporting, or just trying to understand how a complex deck was assembled, this tool turns PowerPoint into something that’s easier to work with programmatically—without sacrificing usability for power.
This project started as an experiment, but it’s quickly becoming a core tool in our tech toolbox. And we think others might find it just as useful.
In addition, parsing pptx files is just one example. Any XML file, i.e. any Office *x file, can be parsed like this and any xml variant like XSD, for example. See also our XSD2XLSX approach.
Want to know more about the project?
Check out the source code:
Original parser: https://github.com/andreas-buehlmeier/pptx-parser
Extended version with link validation: github.com/RaresVelnic/pptx-parser-extended
Check our Youtube Videos:
Original video: https://youtu.be/NRIaaqDFLOw
Video on the extended version: https://www.youtube.com/watch?v=ICafxg14XNc